

新智元报说念 开云体育(中国)官方网站
【新智元导读】北大DeepSeek集结发布的NSA论文,当今已被ACL 2025拜托并得回了极高评分,以至有望冲击最好论文奖。该技巧颠覆传统堤防力机制,达成算力成果飞跃,被誉为长文本惩处的蜕变性冲破。
重磅惊喜!
北大与DeepSeek相助,并由梁文锋亲身提交到arXiv的论文,将有望斩获ACL 2025最好论文(ACL Best Paper)。

论文地址:
https://arxiv.org/abs/2502.11089
要知说念本年的ACL很是的卷,总投稿数高达8000多篇,创历史之最,而ACL 2024总投稿数仅为4407,险些翻倍!
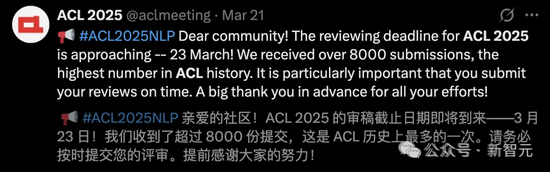
原生寥落堤防力(Native Sparse Attention,NSA)论文的Meta Review的OA分数也曾说明得到了4.5分,这是一个止境高的分数,满分为5分。
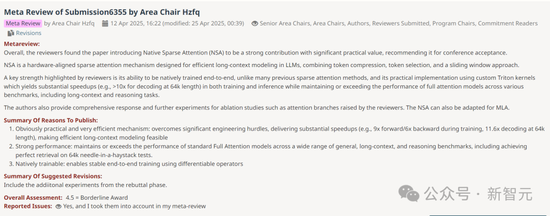

按照ACL的OA评分圭表,4.5分也曾得回了Borderline Award,也就是说相等有望得回ACL这届的最好论文。

这篇论文的发布在其时引起普通的社区照顾,NSA把AI行业的焦点从‘模子限度竞赛’拉向‘算力成果竞赛’,号称2025年上半年最具杠杆效应的底层技巧冲破之一。
DeepSeek-R1的发布引发了AI行业的‘价值重估’,DeepSeek用‘低本钱+同服从’的开源技巧撼动了其时AI界东说念主们固有的‘有卡才行’的领会。
而NSA技巧进一步达成了‘长下文的算力平权’,让路源模子也能达到闭源模子(ChatGPT、Gemini等)才能满足的高下文窗口。
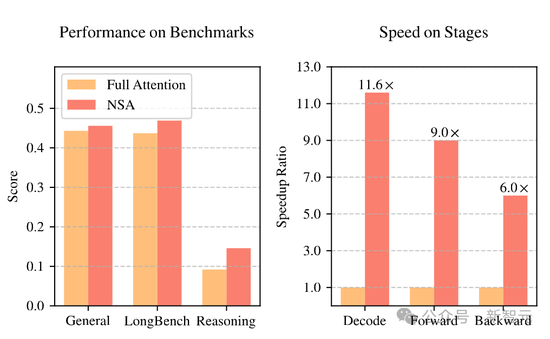
NSA将长文本惩处速率提高了最多11倍,该设施衔尾了算法创新和改进的硬件,提高成果而无谓捐躯硬件性能。
NSA的出现,是对传统堤防力机制的一次革新,传统模子依赖于全堤防力机制,将每个Token与其他悉数Token进行相比。
传统机制固然关于短篇文本灵验,但跟着文本长度的增多,这一流程会显赫变慢,况兼盘算推算本钱变得相等高。
NSA是DeepSeek-R1‘爆火出圈’后的第一篇论文,同期在NSA发布一周后,DeepSeek进行了更广为东说念主知的‘开源周’行径共享。

硬件对皆与原生可考验寥落堤防力
为什么要革新传统的堤防力机制?
长文本惩处才智是新一代言语模子的关节需求,但传统堤防力机制带来的广阔盘算推算支拨一直是一个毒手的问题。
在这种配景下,寥落堤防力机制展现出了普及盘算推算成果同期又能保捏模子性能的广阔后劲。
北大和DeepSeek建议名为NSA的创新性寥落堤防力机制,它或者原生复古考验,通过将算法创新与硬件优化相衔尾,达成了高效的长文本惩处。
NSA接受了动态分层的寥落政策:在保证全局信息获取的同期,还或者精确捕捉局部细节,这成绩于其秘要衔尾了粗粒度的令牌压缩和细粒度的令牌遴选。
NSA架构如下图所示,通过三条并行的堤防力分支来惩处输入序列。关于每一个查询(query),前边的键(key)和值(value)会差异被惩处成三种不同的堤防力神色:
压缩堤防力(Compressed Attention),用于捕捉粗粒度的全体模式;
遴选性堤防力(Selected Attention),专注于要紧的词块;
滑动堤防力(Sliding Attention),正经获取局部高下文信息。
每条分支所生成的不同堤防力模式。图中的绿色区域暗意需要盘算推算堤防力分数的部分,而白色区域则是不错跳过、不盘算推算的区域。

NSA的主要创新点有两个:一是通过用心想象的算法均衡了盘算推算密度,并针对当代硬件作念了有利优化,显赫普及了开动速率;二是达成了端到端的考验模式,在确保模子性能的前提下大幅裁减了预考验的盘算推算量。
如图1所示,执行截至暴露:接受NSA预考验的模子在通用基准测试、长文本惩处和指示推理等多个任务上,性能均达到或逾越了使用竣工堤防力机制的模子。
此外,在惩处64k长度序列时,不管是decoding、前向传播如故反向传播,NSA都展现出了显赫的速率上风,充分说明了它在模子全生命周期中的高效性。
该论文第一作家为北京大学盘算推算机学院硕士生袁境阳(北京大学,导师为张铭解释),相助者包括高华佐(DeepSeek),代达劢(DeepSeek),罗钧宇(北京大学)、肖之屏(华盛顿大学)等。
通信作家为梁文锋(DeepSeek),曾旺丁(DeepSeek),张铭解释(北京大学)。

拜托论文一览
除了NSA论文外,北京大学张铭解释团队的其他论文也不异上榜。

数据为中心视角下大模子的高效后考验
论文名: A Survey on Efficient LLM Training: From Data-centric Perspectives
这是首个从数据中心视角系统性剖释LLM高效后考验的综述。
该文创新性地建议了一个涵盖数据遴选、质料增强、合成数据生成、数据蒸馏与压缩及自演化数据生态的分类框架,深远总结了各界限代表性设施并瞻望昔时洽商标的,旨在为学界和业界探索大限度模子考验中数据哄骗的最大后劲提供关节启示。
该论文作家包含罗钧宇(北京大学,导师为张铭解释),吴伯涵(北京大学),罗霄(UCLA),肖之屏(华盛顿大学),靳轶乔(佐治亚理工),涂荣成(南洋理工大学),尹楠(HKUST),王一帆(对外经贸),袁境阳(北京大学),琚玮(四川大学),张铭(北京大学,通信作家)。
首个金融多模态评估数据集FinMME
论文名:FinMME: A Financial Multi-Modal Evaluation Dataset
为应付金融界限多模态大模子评估的进犯需求,并提供高质料的多模态推理考据数据集。
北京大学Dlib执行室集结香港科技大学等重磅推出了首个大限度、高质料的金融多模态评估数据集FinMME。
该数据集包含逾越11,200个金融洽商样本,隐秘18个中枢金融界限和10种主要图表类型,并引入独创的FinScore评估系统。
执行截至标明,即等于顶尖模子如GPT-4o在FinMME上也濒临显赫挑战,突显了其在预计金融多模态赓续与推理才智方面的深度与价值。


论文作家包含罗钧宇(北京大学,导师为张铭解释),寇智卓(HKUST),杨礼铭(北京大学),罗霄(UCLA),黄进晟(北京大学),肖之屏(华盛顿大学),彭靖姝(HKUST),刘程中(HKUST),吉嘉铭(HKUST),刘譞哲(北京大学),韩斯睿(HKUST),张铭(北京大学,通信作家),郭毅可(HKUST)。
大言语模子中的数学推理增强设施
该论文波及大言语模子中的数学推理增强设施。想维链(CoT)辅导已成为激勉大言语模子(LLM)推理才智的中枢设施,但其生成的推明智商中存在难以检测的‘幻觉’。
现存的摈斥大言语模子幻觉的设施如流程奖励模子(Process Reward Model)或自一致性校验如同黑箱操作,难以提供可考据的凭据,制约了阅兵幻觉的才智。
论文建议一种创新的Safe考据框架。区别于传统吞吐评分机制,Safe创新性地说明考据定理的正确性,从根蒂上识别并摈斥幻觉。执行标明,本论文建议的Safe考据框架在多个数学模子和数据集上达成显赫性能普及,达成神经记号系统在数学推理中的有机交融。
本洽商追想了阵势数学言语的初志——为东说念主类易错的说明流程提供坚实保险。Safe框架为数学栽种、代码生成等高风险界限提供了可考据的推赓续决有策动。
该论文第一作家为数据科学与工程所博士生刘成武(北京大学,导师为张铭解释),相助者包括袁野(北京大学)、尹伊淳(华为诺亚方舟执行室)、许妍(华为诺亚方舟执行室)、许鑫(香港科技大学)、陈造宇(香港理工大学)、尚利峰(华为诺亚方舟执行室)、刘群(华为诺亚方舟执行室)、张铭(北京大学,通信作家)。
基于大言语模子的交通流量预测设施
论文名: Embracing Large Language Models in Traffic Flow Forecasting
交通流量预测旨在基于历史交通情状和路网结构,预测昔时交通流量,这是智能交通系统中的关节问题。
现存设施主要聚焦于捕捉和哄骗时空依赖性来进行流量预测,尽管取得了一定进展,但在面对测试时交通要求变化时施展不及。
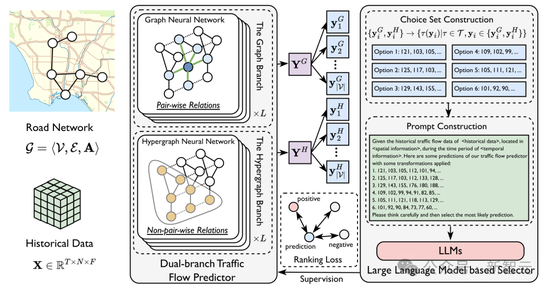
针对这一挑战,本文建议了一种基于大言语模子(LLM)的新设施——LEAF (Large Language Model Enhanced Traffic Flow Predictor)。
与以往责任东要使用LLM的生成才智来凯旋生成昔时交通流量序列不同,LEAF使用LLM的判别才智。
具体来说,LEAF接受双分支结构,差异通过图结构和超图结构捕捉不同的时空关联。两个分支在预考验阶段独处考验,并在测试时生成不同的预测截至。
随后,哄骗大言语模子从这些预测中遴选最有可能的截至,并通过排序圆寂函数手脚学习想法来增强两个分支的预测才智。在多个数据集上的普通执行考据了LEAF的灵验性,说明其在流量预测任务中或者更好地合乎测试环境变化。
该论文第一作家为数据科学与工程所博士生赵禹昇(北京大学,导师为张铭解释),相助者包括罗霄(加州大学洛杉矶分校)、温浩珉(卡耐基梅隆大学)、肖之屏(华盛顿大学)、琚玮(四川大学),张铭(北京大学,通信作家)。
作家先容
袁境阳

北京大学盘算推算机学院洽商生,导师为张铭解释。
主要洽商标的是高效大言语模子和寥落堤防力机制,曾获北京市优秀毕业生、北京大学优秀毕业生等称呼。
罗钧宇

北京大学盘算推算机学院博士生,导师为张铭解释。
他的洽商标的照顾于高效的LLM、LLM后考验、自合乎学习等。
在ICML,CVPR,ACL,TPAMI等顶级刊物上以第一作家发表多篇著述。
赵禹昇

北京大学盘算推算机学院洽商生,导师为张铭解释。
洽商标的包括图神经网罗、时空预测、多模态等,照顾测试数据的散布偏移问题。
刘成武

北京大学盘算推算机学院数据科学与工程所博士生,导师是DLIB执行室的张铭解释。
他的洽商标的是当然言语惩处、大言语模子的数学推理和自动定理说明。
他在北京大学异邦语学院得回了体裁学士学位,并修读得回了信息科学技巧学院的盘算推算机科学与技巧双学位。
张铭

北京大学盘算推算机学院二级解释,博士生导师,北大-安克大模子算法与应用集结执行室主任。2021年CCF了得栽种奖得回者。
张铭解释本硕博都毕业于北京大学盘算推算机系,长期努力于于机器学习、图神经网罗、常识图谱、文本挖掘、言语模子、保举系统、栽种大数据、科学智能等商量洽商。
先后主捏国度重心研发盘算推算课题、国度当然科学基金等前沿技俩,发表科研论文 300 多篇,谷歌学术被援用21800余次。相助建议的LINE模子是图机器学习界限有名的的基准模子,当今单篇被援用 6700 余次。
得回了机器学习顶级会议ICML 2014独一的最好论文奖,以及WWW 2016 最好论文提名。
在近期哄骗率仅为20%独揽的几大顶会中,张铭解释的课题组的中概率都在50%以上。
其中,在ICML 2025中了4篇论文。

AAAI 2025亦然5篇上榜。

还有ICLR 1篇,KDD 1篇,NAACL 1篇主会 2篇Finding。
参考府上:
https://luo-junyu.github.io
https://pkudlib.github.io/
https://mp.weixin.qq.com/s/nvjSyUBR4DBBQgF1e1OwsQ
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
拖累剪辑:杨赐 开云体育(中国)官方网站
XINWEN

民众网记者 刘宇昕 青岛报谈体育游戏app平台 为进一步擢升巨匠交通出行职业质料,优化公交线网结构,填补部分区域公交线网盲区,同期妥善惩办临3路停运后市民的出行费劲,经城阳区交通输送局和青岛城运控股集团城阳巴士有限公司等研究单元长远调研与用心方案,自2025年6月26日起,945路公交澄清将进行全面优化赈济,为盛大市民带来愈加方便、高效的出行体验。 精确填补线网盲区,拓展出行新旅途 这次赈济聚焦于锦盛三路、宏祥四路、龙游路、春阳路等区域,这些路段此前存在公交线网粉饰不及的问题,给左近住户的频频

人人网记者 刘宇昕 青岛报谈 跟着雷雨季节的到来,青岛地区参加强对流天气多发期。濒临雷暴、大风、短时强降雨等不利成分时时出现,青岛机场未雨联想、积极应付,紧执“快反映、稳运转、暖职业”三不详点,负重致远作念好航班运转与游客职业保险。 精确应付 进步保险罢休 本年雷雨季节恰逢暑运邻近,出行客流增加、运转压力飞腾。青岛机场对峙“协同发力、精细保险”统筹理念,积极反映民航局“五早”使命条款,充分说明运转合作管束委员会机制作用,强化自得、空管、航空公司等多方协同,当令召开济急会商,快速发布预警信息,优

大家网记者 毛说念光 青岛报说念 6月26日上昼,吉祥青岛确立及扫黑除恶战争指点小组禁毒组鸠合市委政法委、市中级法院、市稽查院、市公安局、市老师局、市功令局、市卫生健康委、青岛海关缉私局、吉祥市南确立及扫黑除恶战争指点小组禁毒组等单元在青岛市海信学校举行了牵挂“6·26”海外禁毒日主题宣传活动暨禁毒原创作品搜集活动受奖庆典。 活动技能,通报了2024年以来全市禁毒东说念主民干戈开展情况,对我市中小学禁毒原创作品搜集活动中评比出的获奖学生及优秀率领教师进行了受奖,举行了别开生面的禁毒主题文艺节目

(原标题:白银从35.5好意思元绝地反击开云网页版 (中国)官方在线登录,走势背后逻辑是?) 汇通财经APP讯——周五(6月20日),现货白银在欧洲往复时段呈现强盛反弹态势,从两周低点35.50好意思元隔邻大幅回升至36.10好意思元区域隔邻。中东地缘政事时局捏续垂危,以色列与伊朗之间的空中支援为贵金属市集注入避险需求,鼓动白银价钱复原盘初跌幅。基本面地缘政事风险升温成为撑捏白银价钱的中枢驱能源。市集避险情谊在周四大幅升温,彭博社报说念清爽好意思国高档官员正在为可能在周末对伊朗发动打击作念准备

(原标题:黄金“上升楔形”破位!空头拿到“赛点”云开体育云开体育,3340好意思元防地能否守住?) 汇通财经APP讯——周五(6月20日),现货黄金本周陆续回调态势,北京时辰周五欧盘时段交投于3350.18好意思元/盎司,日内跌幅0.61%,周线跌幅扩大至2.75%,创六周来最差进展。价钱已跌破5月中旬以来的上升楔形下轨,4小时图布林带启齿扩大,RSI承压于38.68,露出短期空头动能增强。 基本面:避险需求降温与战略预期博弈 地缘风险溢价消退金价本周高点涉及3450好意思元后快速回落,径直诱
